%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Today, Xiaomi officially announced the release of its embodied large model MiMo-Embodied and declared that the model will be fully open-sourced. This move marks an important step for Xiaomi in the field of general embodied intelligence research.
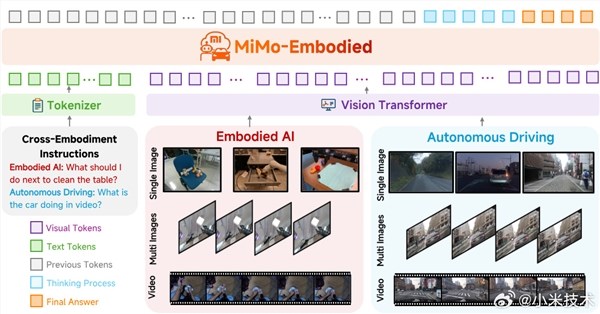
As embodied intelligence gradually takes root in home scenarios and autonomous driving technology scales up, how robots and vehicles can better achieve cognitive and capability interoperability, and whether indoor operational intelligence and outdoor driving intelligence can promote each other, have become key issues that the industry urgently needs to solve. The MiMo-Embodied model released by Xiaomi this time was developed to address these challenges. It successfully bridges the two fields of autonomous driving and embodied intelligence, achieving unified task modeling and making a key breakthrough from "vertical domain-specific" to "cross-domain capability collaboration."

The MiMo-Embodied model has three core technical highlights. First, it has cross-domain capability coverage, supporting three core tasks of embodied intelligence, namely affordance reasoning, task planning, and spatial understanding, as well as three key tasks of autonomous driving, namely environmental perception, state prediction, and driving planning, providing strong support for full-scenario intelligence. Second, the model has verified the knowledge transfer and collaborative effects between indoor interaction capabilities and road decision-making capabilities, offering new ideas for cross-scenario intelligent integration. Finally, MiMo-Embodied adopts a multi-stage training strategy called "embodied/driving capability learning CoT reasoning enhanced RL fine-tuning," effectively improving the model's deployment reliability in real environments.
In terms of performance, MiMo-Embodied has set a new performance benchmark for open-source base models in 29 core benchmark tests covering perception, decision-making, and planning, surpassing existing open-source, closed-source, and specialized models. In the field of embodied intelligence, the model achieved SOTA results on 17 benchmarks, redefining the boundaries of task planning, affordance prediction, and spatial understanding. In the field of autonomous driving, it performed excellently on 12 benchmarks, achieving a full-chain performance breakthrough in environmental perception, state prediction, and driving planning. Moreover, in the general visual language field, MiMo-Embodied also demonstrated excellent generalization ability, further achieving significant performance improvements on multiple key benchmarks while strengthening general perception and understanding capabilities.
Open source address:
https://huggingface.co/XiaomiMiMo/MiMo-Embodied-7B