%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://app.aibase.com/zh
1、阿里巴巴开源 Z-Image 图像模型:支持中英双语文字渲染
阿里巴巴通义实验室开源了全新的图像生成模型 Z-Image,凭借仅 6B 参数规模实现了高效的图像生成与编辑,视觉质量接近三倍参数级别的商业模型。其轻量化架构和高效性能使其适用于消费级设备,并在复杂指令理解和双语渲染方面表现出色。
![]()
【AiBase提要:】
🔥 Z-Image 采用单流 DiT 架构,包含 Turbo、Base 和 Edit 三种变体,满足不同需求。
💡 支持中英双语文字渲染,解决传统 AI 模型在文本处理上的痛点。
🚀 显存占用低至 16GB,可在消费级显卡上流畅运行,提升图像生成效率。
详情链接:https://tongyi-mai.github.io/Z-Image-homepage/
2、夸克AI眼镜发布:搭载双旗舰芯片 接入阿里千问
夸克AI眼镜的发布标志着阿里千问首次进入物理世界,通过硬件升级和创新技术,为用户提供更高效、便捷的AI体验。

【AiBase提要:】
📱搭载双旗舰芯片,提升千问的响应速度和性能表现。
📷引入手机级影像能力,增强暗光环境下的拍摄画质与稳定性。
🔋采用双电池可换电设计,确保长时间在线待命。
3、Opera Neon 浏览器大升级:1分钟出研报+Gemini3一键切+Google Docs秒写
Opera Neon浏览器推出重大更新,新增‘1分钟深度研究’模式,集成Gemini3Pro与Nano Banana Pro双模型,并首次支持自然语言创建与编辑Google Docs。该功能提升了用户在快速查询和全面研究之间的效率,同时为文档编写提供了自动化解决方案。
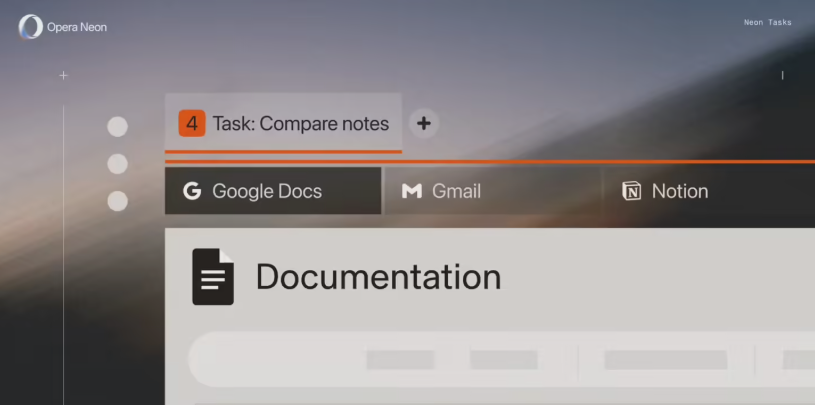
【AiBase提要:】
✨ 新增‘1分钟深度研究’模式,提升复杂问题处理效率。
🔄 支持Gemini3Pro与Nano Banana Pro模型切换,灵活应对多阶段任务。
📝 集成Google Docs智能体,实现自然语言操作文档,提高写作效率。
4、清华大学发布 AI 应用指导原则:禁止将 AI 生成内容用作学业成果
清华大学正式发布了《清华大学人工智能教育应用指导原则》,旨在规范校园内人工智能的使用。该指导原则首次系统性地提出了人工智能应用的全局性和分层级的引导规范,涵盖了教学及学术研究的各个核心场景。
【AiBase提要:】
🧠 清华大学发布人工智能教育应用指导原则,规范校园内 AI 使用。
📚 指导原则强调严禁将 AI 生成的内容作为学业成果,确保学术诚信。
🔍 学校鼓励教师与学生积极探索 AI 辅助学习,但需遵循明确的使用规范。
5、DeepMind发布“Gemini 3 Pro系统指令”:Agent任务成功率提升5%,多步骤工作流可靠性工程化
DeepMind公开了Gemini 3 Pro的专属System Instructions,显著提升了大模型在多个基准测试中的表现。该指令强调逻辑推理、风险评估和持久性,标志着大模型从‘黑箱调参’迈向‘工程化指令’阶段。
【AiBase提要:】
📌 Gemini 3 Pro的System Instructions提升了Agent任务成功率约5%。
🔍 指令强调逻辑依赖、风险评估和假设探索,增强模型的可靠性。
🚀 DeepMind计划将指令封装为可配置JSON Schema,并在2026年Q1开放给Vertex AI等平台。
6、Adobe 发布 Project Graph:重塑创意工作流的 AI 工具
Adobe 推出的 Project Graph 是一个基于节点的视觉化编辑器,旨在帮助艺术家和设计师更高效地自定义创作流程。它通过将 AI 模型、工具和效果器连接起来,提升了创作的可控性和精确度,并支持将复杂的工作流打包为可分享的工具,从而提升团队协作效率。
【AiBase提要:】
🎨 Adobe 推出 Project Graph,旨在重塑 AI 时代的创作工作流。
🛠️ 该系统使用节点编辑器,让用户像搭积木一样自定义创作流程。
📦 用户可将创意工作流打包成可分享的工具,便于团队协作和应用。
详情链接:https://www.adobe.com/express/create/chart/bar
7、新型聊天式提示词工具 YPrompt ,轻松生成专业 Prompt
YPrompt 是一款创新的聊天式提示词工程工具,通过与用户的对话深入挖掘需求,自动生成专业的提示词。它不仅支持多种输出格式,还具备强大的版本管理功能,让用户在创作过程中更加高效和灵活。
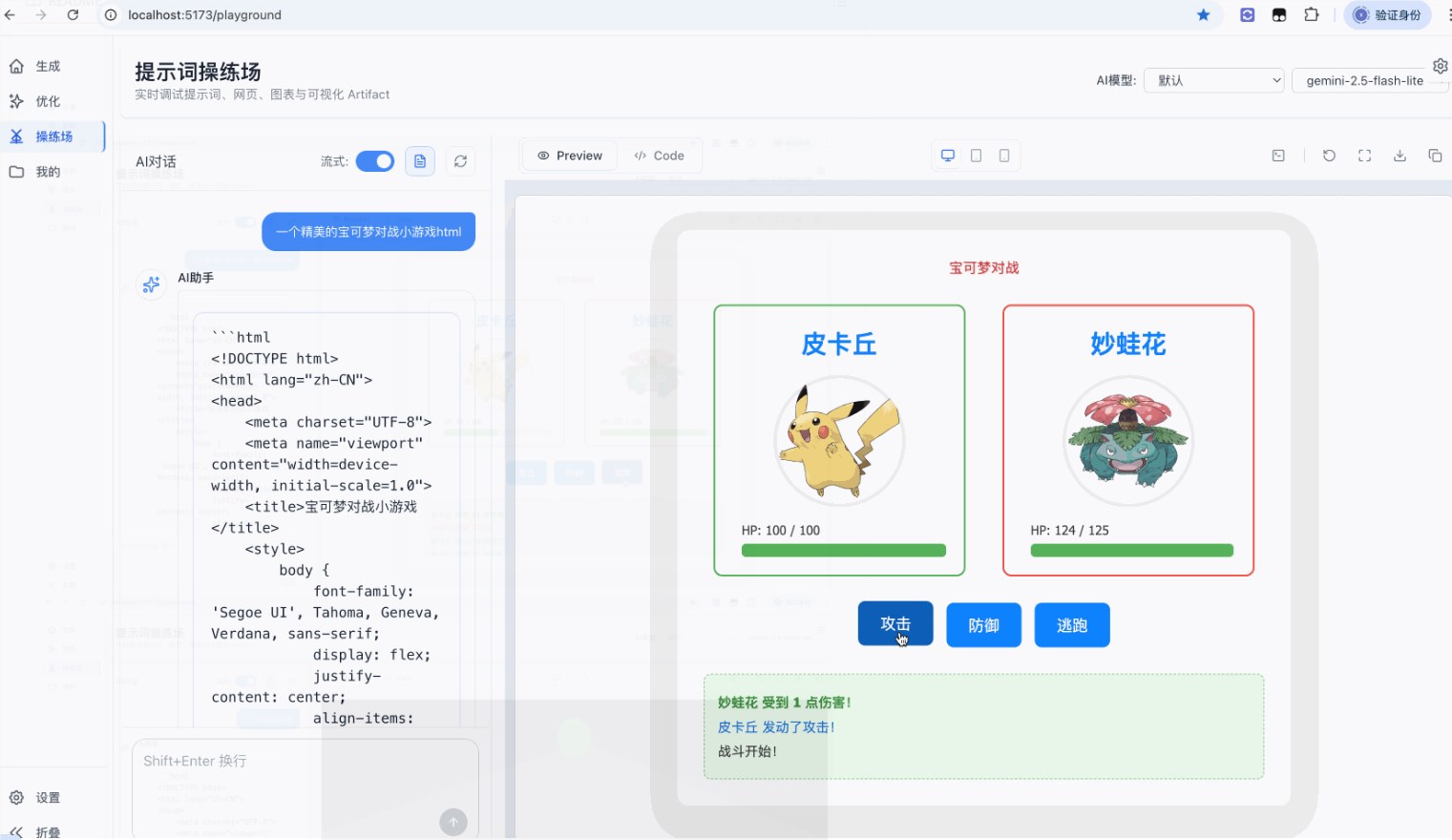
【AiBase提要:】
✨ YPrompt 是一个聊天式提示词生成工具,通过对话挖掘用户需求。
🛠️ 该工具支持多种输出格式,方便用户即时查看效果。
📈 每次修改都会记录版本,用户可随时对比和回滚。
详情链接:https://github.com/fish2018/YPrompt
8、巨人网络发布三大 Muli-Modal 模型:消除视频畸变,歌声转换实现“真实歌曲可用”
巨人网络AI Lab联合清华大学SATLab、西北工业大学推出三项音视频多模态生成技术成果,包括音乐驱动的视频生成模型YingVideo-MV、零样本歌声转换模型YingMusic-SVC与歌声合成模型YingMusic-Singer,展示了团队在音视频多模态生成领域的最新进展,并计划开源这些技术。
【AiBase提要:】
🎥 音乐驱动的视频生成模型 YingVideo-MV 可通过一段音乐和一张人物图像生成高质量的音乐视频片段。
🎤 零样本歌声转换模型 YingMusic-SVC 实现了“真实歌曲可用”的歌声转换能力,有效抑制干扰并降低破音风险。
🎵 歌声合成模型 YingMusic-Singer 支持输入任意歌词生成自然歌声,具备零样本音色克隆功能,提升创作灵活性。