研究發現,GPT-4 在“現實世界的務實任務”中主導了其他LLM

THE DECODER
發布於AI新聞資訊 · 1 分鐘閱讀 · Jul 25, 2025
《解碼器》的研究團隊開發了一個名爲 AgentBench 的基準測試,用於衡量大語言模型在輔助任務中的能力。通過測試 25 個語言模型,他們發現 GPT-4 在綜合得分和各個領域中表現最佳。該研究團隊還提供了工具包、數據集和基準測試環境,供研究社區使用。這項研究的結果對於進一步評估其他商業和開源模型的性能非常有價值。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

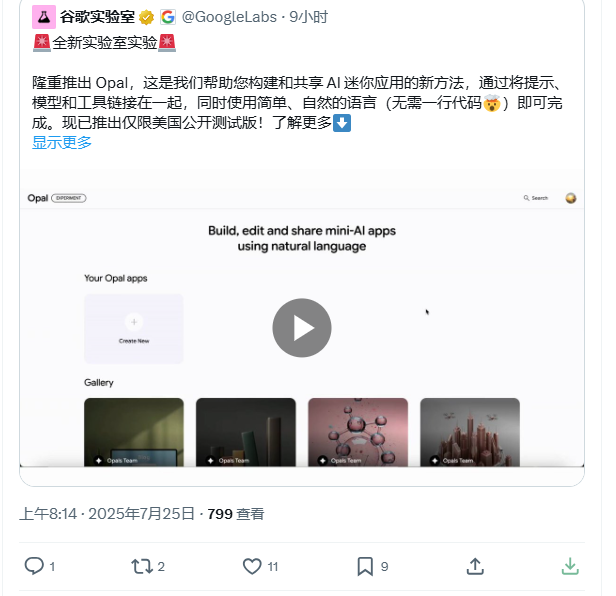
谷歌實驗室推出實驗性AI工具Opal,支持零代碼開發AI應用。該工具通過自然語言指令和可視化編輯器,讓用戶無需編程即可構建AI驅動的迷你應用。核心功能包括自然語言驅動、可視化工作流編輯、谷歌AI生態集成及協作分享。目前僅限美國IP用戶公測,未來或向全球開放。Opal降低了AI開發門檻,是谷歌推動AI民主化的重要嘗試,有望重塑AI應用開發格局。

東南俄克拉荷馬大學最新調查顯示,約1/3美國人正使用ChatGPT等AI工具輔助職業轉型。調查覆蓋1000名不同世代人羣,發現超半數受訪者考慮轉行,其中Z世代意願最強(57%)。AI主要被用於撰寫簡歷(43%)、研究工作機會(47%),18%的人通過AI發現新職業方向。但60%受訪者更信任人類顧問,僅7%完全相信AI建議。專家預測AI將在5年內取代半數白領工作,科技公司已減少應屆生招聘,同時高薪爭奪AI頂尖人才。


谷歌搜索專家在直播會議中強調,AI技術已深度融入搜索各環節但SEO基本原則不變。核心觀點包括:1)AI功能基於傳統搜索架構,現有SEO策略仍適用;2)谷歌不區分人工/AI內容,只關注質量與可信度;3)BERT、RankBrain等AI模型參與爬取、索引、排名全流程;4)AI摘要功能使普通結果點擊率從15%降至8%,源鏈接點擊僅1%。關鍵影響:雖然技術規則未變,但AI摘要導致網站流量顯著下降,傳統內容曝光度降低。