%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

8月11日,智譜科技正式推出其最新的視覺理解模型 ——GLM-4.5V。這款模型是基於其新一代文本模型 GLM-4.5-Air 進行訓練的,繼承了上一代視覺推理模型 GLM-4.1V-Thinking 的技術路線,擁有驚人的1060億參數和120億激活參數。值得一提的是,GLM-4.5V 還新增了 “思考模式” 開關功能,用戶可以選擇是否啓用該模式,從而在處理任務時更靈活。
這一模型的視覺能力令人矚目,能夠輕鬆分辨出麥當勞和肯德基的炸雞翅,從外觀色澤和質感等多個角度進行深入分析。此外,GLM-4.5V 還能參與圖像猜地點的挑戰,甚至在比賽中取得了優異的成績,超越了99% 的人類參賽者,位列第66名。智譜還展示了該模型在42個基準測試中的卓越表現,在絕大多數測試中得分超過同等規模的其他模型。
目前,GLM-4.5V 已經在開源平臺如 Hugging Face、魔搭和 GitHub 上線,用戶可以免費下載使用,並且還提供了 FP8量化版本。爲了更好地體驗這一模型,智譜推出了一個桌面助手應用程序,支持實時截屏和錄屏,幫助用戶完成各種視覺推理任務,包括代碼輔助和文檔解讀。
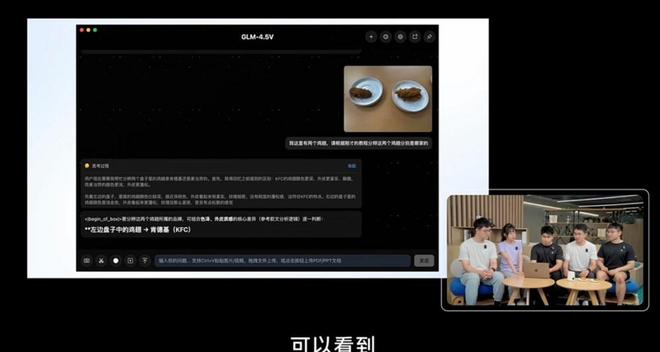
在實際測試中,GLM-4.5V 展現了出色的能力,能夠根據上傳的圖片進行位置推斷,雖然偶爾會出現小誤差,但推理過程仍然非常豐富。而在處理網頁內容時,它可以通過截圖生成相似度高的頁面,展現出強大的復現能力。

GLM-4.5V 不僅在視覺理解領域表現突出,還在 Agent 應用場景中展現出巨大潛力。隨着這一技術的不斷髮展,我們有理由期待它在未來的應用中爲人們的生活帶來更多便捷。