%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

中国AI企業のMiniMaxは正式に最新の大型言語モデル(LLM)であるMiniMax-M1をオープンソースとして発表しました。このモデルは超長文の文脈推論能力と効率的なトレーニングコストで世界的な注目を集めています。AIbaseが最新情報を整理し、MiniMax-M1の詳細な解説をお届けします。
記録破りの文脈ウィンドウ: 100万入力、8万出力
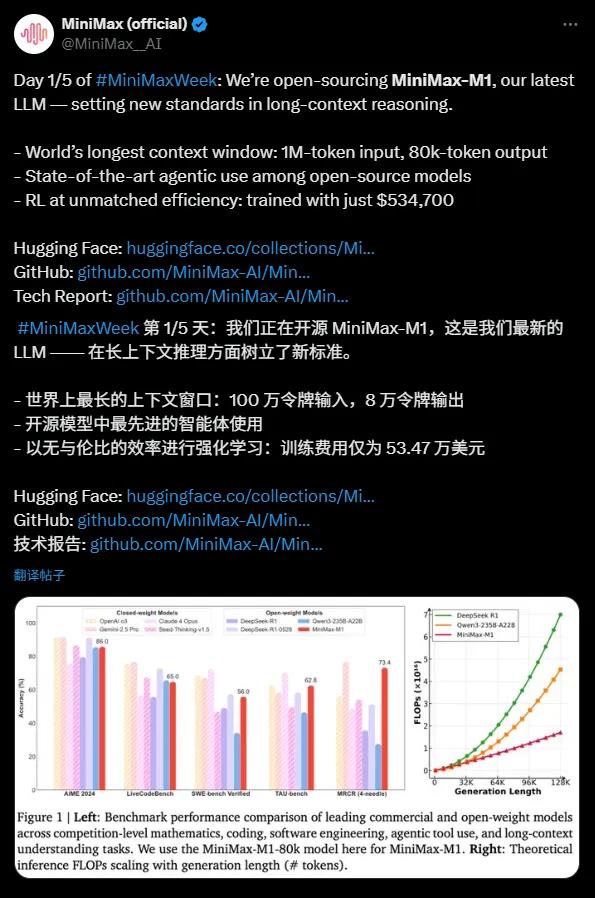
MiniMax-M1は驚異的な100万トークンの入力と8万トークンの出力を持つ文脈ウィンドウを持ち、現在のオープンソースモデルの中で最も優れた長文推論能力を備えています。この能力により、モデルは一回で小説やシリーズ全体ほどの情報量を処理できるため、OpenAI GPT-4の128,000トークンの文脈ウィンドウを超えることができます。複雑なドキュメントの分析、長いコードの生成、あるいはマルチラウンド対話においても、MiniMax-M1は自在に対応し、企業や開発者にとって強力なツールとなっています。
代理能力のリーダー: オープンソースモデルの中でも際立つ
MiniMax-M1は代理ツールの利用において卓越したパフォーマンスを示し、OpenAI o3やClaude4Opusなどのトップレベルの商用モデルと同等の能力を発揮しています。混合専門家モデル(MoE)アーキテクチャとLightning Attentionメカニズムの組み合わせにより、MiniMax-M1はソフトウェアエンジニアリングやツール呼び出し、長文推論といった複雑なタスクで最先端のパフォーマンスを達成しています。この強力な代理能力を持つオープンソースモデルは、グローバルな開発者コミュニティに新しい機会をもたらしました。

高コスパ: 前沿のLLMを53万ドルで実現
MiniMax-M1のトレーニングコストは目を見張るものがあり、わずか53.47万ドルです。DeepSeek R1の500万〜600万ドルやOpenAI GPT-4の1億ドル以上に比べて、「手頃な価格の奇跡」といわれています。効率的な強化学習(RL)技術と512個のH800 GPUによるハードウェアサポートにより、MiniMaxはたった3週間でモデルを開発しました。さらに、MiniMax独自のCISPO最適化アルゴリズムによって、推論効率が向上し、重要な情報を失うことなくトレーニングコストを削減しました。
技術のハイライト: 4560億パラメーターと効率的なアーキテクチャ
MiniMax-M1はMiniMax-Text-01に基づいており、総パラメーター数は4560億に達します。各トークンの活性化には約45.9億のパラメーターを使用し、MoEアーキテクチャにより効率的な計算を実現しています。モデルは40kと80kの思考予算を持つ2種類の推論モードをサポートしており、異なるシナリオに対応できます。数学やコーディングなど推論密度の高いタスクでは、MiniMax-M1はDeepSeek R1やQwen3-235B-A22Bなどのモデルを上回るパフォーマンスを示しています。
オープンソースエコシステムのマイルストーン
MiniMax-M1はApache2.0ライセンスに基づいており、Hugging Faceプラットフォームに公開され、世界中の開発者が無料で使用できます。この取り組みはDeepSeekなどの中国のAI企業が提供するオープンソースモデルに挑戦し、グローバルなAIエコシステムに新たな活力を注入しました。MiniMaxは今後さらなる技術的詳細を公開し、オープンソースコミュニティの革新を促進すると表明しています。
MiniMax-M1の発表は、長文推論と代理能力におけるオープンソースAIモデルの大きなブレークスルーを象徴しています。その超長文ウィンドウ、効率的なトレーニングコスト、そして強力なパフォーマンスにより、企業や開発者に非常にコストパフォーマンスの高いソリューションを提供しています。AIbaseは、MiniMax-M1のオープンソース化が複雑なタスクでのAI技術の応用を加速し、グローバルなAIエコシステムを新たな高みへと導くことを確信しています。