%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

中國AI公司MiniMax正式宣佈開源其最新大型語言模型(LLM)MiniMax-M1,該模型以超長上下文推理能力和高效訓練成本引發全球關注。AIbase整理最新信息,爲您帶來MiniMax-M1的全面解讀。
創紀錄的上下文窗口:1M輸入,80k輸出
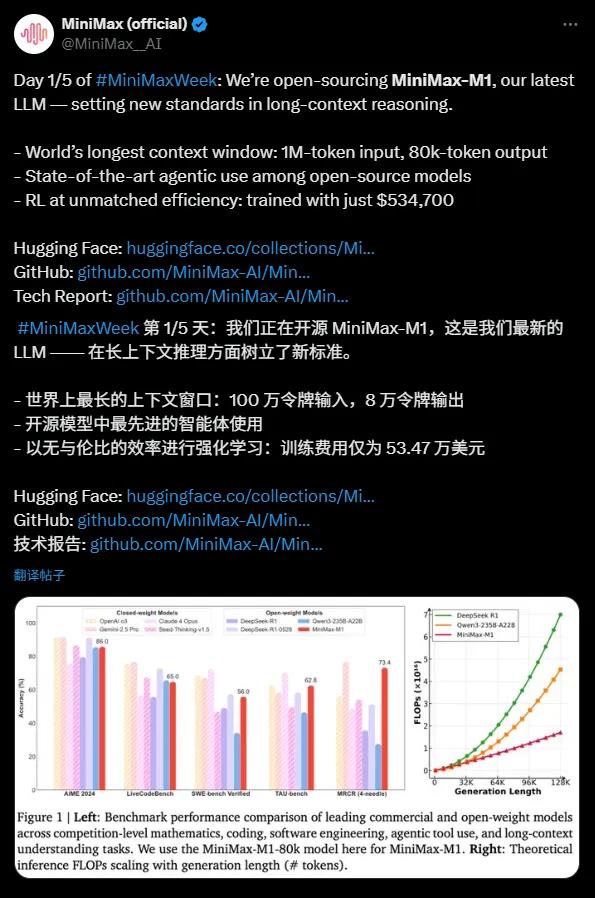
MiniMax-M1以其驚人的100萬token輸入和8萬token輸出的上下文窗口,成爲目前開源模型中最擅長長上下文推理的佼佼者。這一能力意味着模型能夠一次性處理相當於一本小說甚至整個書系列的信息量,遠超OpenAI GPT-4o的128,000token上下文窗口。無論是複雜文檔分析、長篇代碼生成,還是多輪對話,MiniMax-M1都能遊刃有餘,爲企業和開發者提供了強大的工具。
開源模型中的代理能力先鋒
MiniMax-M1在代理工具使用方面表現卓越,性能媲美頂級商業模型如OpenAI o3和Claude4Opus。得益於其混合專家模型(MoE)架構與Lightning Attention機制的結合,MiniMax-M1在複雜任務如軟件工程、工具調用和長上下文推理中展現出接近最先進的性能。這種開源模型的強大代理能力,爲全球開發者社區帶來了前所未有的機會。

超高性價比:53萬美元打造前沿LLM
MiniMax-M1的訓練成本令人矚目,僅需53.47萬美元,相比DeepSeek R1的500-600萬美元和OpenAI GPT-4的超1億美元,堪稱“平價奇蹟”。通過高效的強化學習(RL)技術和僅512個H800GPU的硬件支持,MiniMax在短短三週內完成了模型開發。此外,MiniMax首創的CISPO優化算法進一步提升了推理效率,確保重要信息不丟失,同時降低訓練成本。
技術亮點:456億參數與高效架構
MiniMax-M1基於MiniMax-Text-01開發,擁有4560億總參數,每個token激活約45.9億參數,通過MoE架構實現高效計算。模型支持40k和80k思維預算的兩種推理模式,滿足不同場景需求。在數學、編碼等推理密集型任務的基準測試中,MiniMax-M1表現強勁,超越了DeepSeek R1和Qwen3-235B-A22B等模型。
開源生態的里程碑
MiniMax-M1採用Apache2.0許可證,已上架Hugging Face平臺,供全球開發者免費使用。這一舉措不僅挑戰了DeepSeek等中國AI企業的開源模型,也爲全球AI生態注入了新的活力。MiniMax表示,未來還將發佈更多技術細節,進一步推動開源社區的創新。
MiniMax-M1的發佈標誌着開源AI模型在長上下文推理和代理能力上的重大突破。其超長上下文窗口、高效訓練成本和強大性能,爲企業和開發者提供了極具性價比的解決方案。AIbase認爲,MiniMax-M1的開源將加速AI技術在複雜任務中的應用,推動全球AI生態邁向新高度。