%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

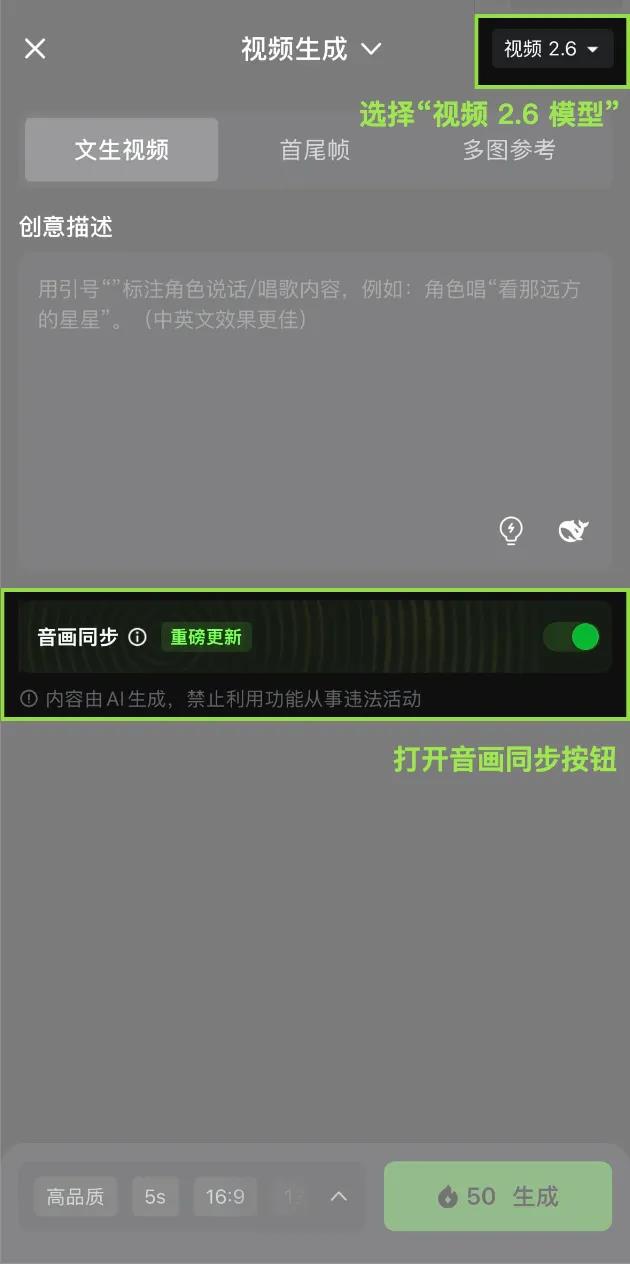
快手の子会社であるKuaishou AIは、公式WeChat公众号で初めての「音画同出」モデルであるKuaishou 2.6を発表しました。このモデルの特徴は、一度の生成プロセスで画像、自然な声、効果音、環境の雰囲気を同時に生成できることです。これにより、「音」と「画」の世界を完全に統合し、ユーザーのクリエイティブな体験を向上させます。
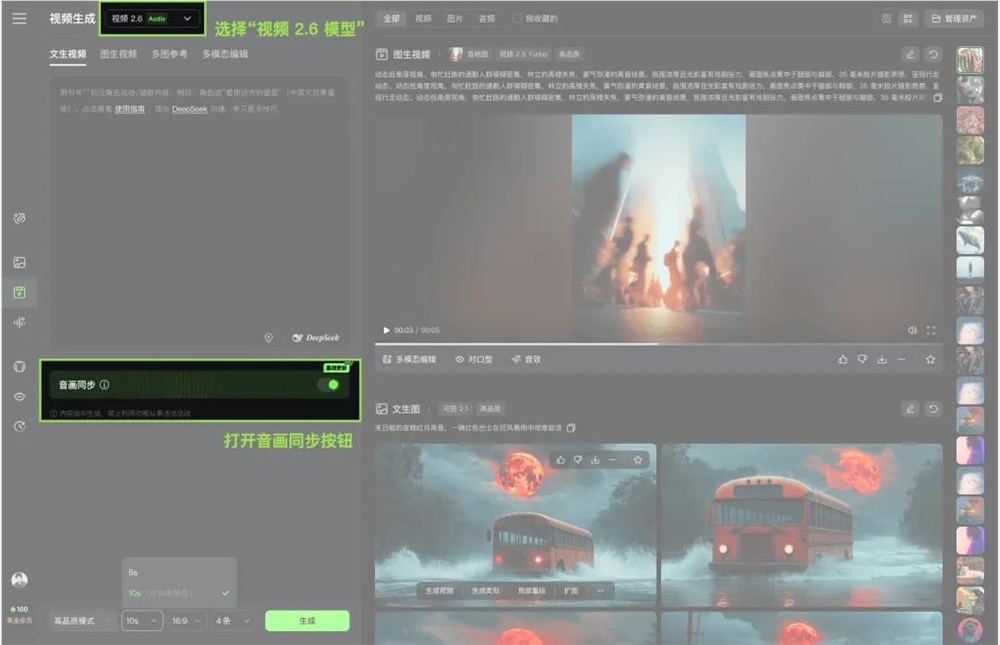
Kuaishou 2.6には「テキストから音画を生成する」および「画像から音画を生成する」2つの創作ルートが用意されています。「テキストから音画を生成する」機能では、簡単な一文だけで、完全な音声・映像コンテンツを迅速に生成できます。一方、「画像から音画を生成する」機能は、静止画を「話す」ようにし、動的に表現します。つまり、ユーザーはテキストまたは画像を提供するだけで、豊富な音声・映像作品を作成することができます。
このモデルは幅広い応用シーンを持ち、さまざまな形式のコンテンツ制作に適しています。例えば、単人独白(商品紹介、生活Vlog、ニュースキャスター、スピーチ)、ナレーション(商品説明、試合解説、ドキュメンタリー、物語)、多人数対話(インタビュー番組、ショートドラマ)、音楽パフォーマンス(歌唱、ラップ、複数合唱、楽器演奏)などです。
Kuaishou AIは、2.6バージョンのリリースによって、ビデオ制作がより柔軟かつ使いやすくなると述べています。ユーザーは自分のアイデアや創造性をよりよく表現できるようになります。今回のモデルのリリースは、快手がAI創作分野でさらに前進したことを示しており、ユーザーの増加するコンテンツ制作ニーズをより満たすものです。
注目ポイント:
🎨 Kuaishou 2.6モデルは音画同期生成を実現し、ユーザーの創作体験を向上させます。
🖊️ 「テキストから音画を生成する」および「画像から音画を生成する」2つの創作ルートを提供し、多様なコンテンツ形式に対応します。
🎤 独白、ナレーション、対話、音楽パフォーマンスなど、多くのシナリオに適用可能です。