%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

【AIニュース】へようこそ!ここは毎日人工知能の世界を探索するためのガイドです。毎日、AI分野の注目ニュースをお届けし、開発者に焦点を当て、技術トレンドやイノベーティブなAI製品・アプリケーションの理解をお手伝いします。
新鮮なAI製品クリックして詳細を確認:https://www.aibase.cn/
1. 智譜GLM-4.5Vのオープンソースリリース:グローバル100B級で最高のビジュアル推論モデル
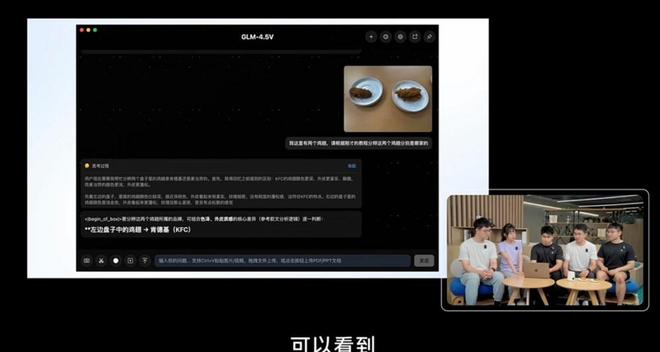
智譜は、世界で最も効果的なオープンソースのビジュアル推論モデルであるGLM-4.5Vをリリースし、オープンソース化しました。これは、同社が汎用人工知能(AGI)への道を歩む上でまた一つ重要な前進的な成果です。
【AiBaseの要点:】
🤖 GLM-4.5Vの総パラメータ数は106Bで、41の視覚マルチモーダルベンチマークでSOTA性能を達成しています。
🎯 全てのシナリオにおけるビジュアル推論能力を備えており、画像推論、動画理解、GUIタスクなどに対応しています。
💡 新たな「思考モード」スイッチを追加し、効率と結果のバランスを取っています。
💰 API料金は入力が2元/M tokens、出力が6元/M tokensまで低価格です。
2. アリババ・ダーモ研究院が3つのエージェントインテリジェンスのコア技術をオープンソース化
世界ロボット大会で、アリババ・ダーモ研究院は独自開発した3つのコア技術をオープンソース化しました。それは、VLAモデルRynnVLA-001-7B、世界理解モデルRynnEC、およびロボットコンテキストプロトコルRynnRCPです。この取り組みは、データ、モデル、ロボット本体の互換性を促進し、エージェントインテリジェンス開発の完全なプロセスを実現することを目的としています。
【AiBaseの要点:】
🚀 3つのコア技術をオープンソース化:VLAモデル、世界理解モデル、ロボットコンテキストプロトコル
🔗 RynnRCPはセンサデータからロボット動作の実行までの完全な作業フローを実現します。
👁️ RynnVLA-001は第一人称視点の動画を通じて人間の操作スキルを学習します。
🌍 RynnECは11の次元からシーン内の物体を全面的に解析し、3Dモデルに依存せず動作します。
詳細リンク:https://github.com/alibaba-damo-academy/RynnRCP
3. アップルがApple IntelligenceをGPT-5へアップグレードし、Siriとライティングツールのスマート化を推進
アップル社は、近日リリース予定のiOS26、iPadOS26、macOS Tahoe26のシステム更新において、Apple Intelligence内のChatGPTコアモデルを最新のGPT-5バージョンにアップグレードすると発表しました。
【AiBaseの要点:】
🚀 iOS26などのシステム更新で、ChatGPTモデルをGPT-5にアップグレードし、Siri、ライティングツール、ビジュアルインテリジェンスの性能向上を図ります。
🚀 新バージョンでは、多言語リアルタイム翻訳と画面内容分析機能が導入され、デバイスの多言語コミュニケーションおよび情報処理能力が強化されます。
🚀 デバイス側APIも初めて開発者向けに公開され、サードパーティアプリとの統合により、低遅延かつ高プライバシーなAI体験を提供します。
4. 高徳が通義大モデルを全面的に統合し、最初のマップAIネイティブエージェントをリリース
アリババグループの高徳マップは、通義ラボと共同で世界初のAIネイティブマップをリリースし、「小高先生」というスマートエージェントを登場させ、全链路音声対話と複雑なタスク推論ナビゲーションを実現しました。
【AiBaseの要点:】
🎙️ 内蔵されたスマートエージェント「小高先生」は、音声/テキストなどのマルチモーダルインタラクションをサポートし、いつでも中断可能な双方向音声を実現します。
🧠 36兆トークンで事前に学習されたQwen大モデルを基盤として、空間的意味の深い理解と数百種類の内部ツールの効率的な調達を実現します。
🗂️ 複雑なPOI推論エージェントを共同でリリースし、多重制約を分解し、リアルタイム情報を統合し、正確な推奨とナビゲーションを提供します。
🔍 自社開発のDeepResearchフレームワークを基盤とし、計画、反省、ツール呼び出しなどの完全なエージェント機能を持っています。
5. 宇樹科技が初回世界人形ロボット選手権に出場し、ハードウェアが多数のチームに採用される予定
宇樹科技は、8月14日から17日にかけて初回世界人形ロボット選手権に参加する予定です。宇樹は、自チーム以外にも、複数のチームが宇樹のロボットハードウェアを使用して競技を行うことを明らかにしましたが、それぞれのチームが独自のアルゴリズムを搭載する予定です。

【AiBaseの要点:】
🤖 自チーム以外にも、複数のチームが宇樹のロボットハードウェアを使用して競技を行う予定ですが、それぞれのチームが独自のアルゴリズムを搭載する予定です。
🏟️ この大会には、天工、加速進化、松延動力、フォーリー、星海図などの国内トップの人形ロボット企業だけでなく、アメリカ、ドイツ、オーストラリア、ブラジル、日本など16カ国の280チームが参加しています。
🔧 宇樹科技の参加は、人形ロボットハードウェアにおける実力を示すだけでなく、オープンエコシステムでの広範な適用と競争力も示しています。
6. Claude AIが歴史的な会話記憶機能をリリースし、複数の背景切り替えをサポート
AnthropicはClaude AIに「記憶機能」をリリースし、ユーザーの過去の会話における背景情報を自動的に記憶・再利用し、複数の会話間でスムーズに接続し、複数の背景を隔離・切り替えることができます。現在は有料ユーザーのみが利用可能です。
【AiBaseの要点:】
🔄 異なるプロジェクトに対して独立した背景を設定でき、仕事/生活のシナリオを一括で切り替えることができ、文脈を維持できます。
💰 初期段階ではClaude Max、Team、Enterpriseの有料ユーザーが対象であり、Pro版は後ほど対応予定で、無料ユーザーは現時点では利用できません。
⚙️ ユーザーは「設定—検索と参照チャット」で手動で記憶を有効化または確認できます。
🤖 ChatGPTの手動設定とは異なり、Claudeは自動抽出機構を使用しており、より「無感覚」な体験を提供しますが、制御性はやや劣ります。
7. 360知脳がLight-IFシリーズモデルをリリースし、複雑な指示の遵守能力を顕著に向上
360知脳はLight-IFシリーズモデルを発表し、「プレビュー-自己検査型推論+情報エントロピー制御」フレームワークによって「怠惰な推論」を専門に治療し、4つの主要ベンチマークで全体的に優位に立ち、小さなパラメータで大規模モデルを越えており、すべてオープンソース化されています。
【AiBaseの要点:】
🎯 イノベーティブなLight-IFフレームワーク:難易度感知指令生成→Zero-RL強化→推論モードフィルタリング→エントロピー保持冷起動→エントロピー適応正則、著しく「単に繰り返すだけではなくチェックしない」怠惰な推論を抑制します。
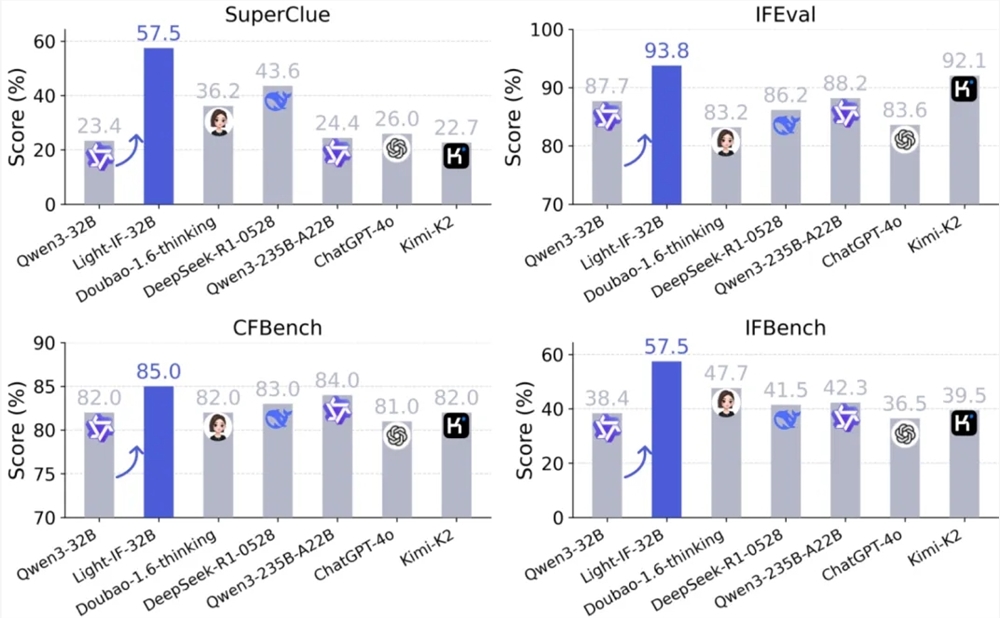
📈 权威的な評価で上位を独占:Light-IF-32BはSuperCLUEで0.575を獲得し、2番目の順位と13.9ポイントの差をつけています;Light-IF-1.7Bの小モデルはQwen3-235B-A22Bなどの超大規模モデルを逆転しています。
🔓 全面的なオープンソース:モデル重みは徐々にHugging Faceに掲載され、冷起動データセットとトレーニングコードはGitHubに同時に公開され、SuperCLUEとともに中国語評価基準SuperCLUE-CPIFOpenを共同でリリースします。
8. ビットテックがビデオ字幕の痕跡なし消去ソリューションをリリースし、DiT大規模モデルに基づいています
ビットテックは、世界で初めてDiT大規模モデルに基づいた「ビデオ字幕の痕跡なし消去」ソリューションをリリースし、ピクセル単位の修復、多言語対応、ワンクリック「消去-翻訳-口元同期」を実現し、短編ドラマの海外展開やECのグローバル化を支援します。

【AiBaseの要点:】
🎞️ 2つのコア技術:DiTビデオ字幕消去大規模モデル+フォントレベルの分割モデル、ピクセル単位の正確な修復、マゼッタやぼかしや点滅を回避します。
🌐 多言語サポート:中国語と英語に限らず、小語種もカバーし、「消去-翻訳-口元同期」のワンストップ閉ループを形成します。
⚙️ 工程実装:万枚データで検証され、成功率は100%;分散されたスクリーンごとの計算により、効率が何倍も向上します。
詳細アドレス:https://console.volcengine.com/vod/
9. 昆崙万維がオープンソース世界モデルMatrix-Game2.0をリリース:1分間の連続した高連続性動画をリアルタイムで生成
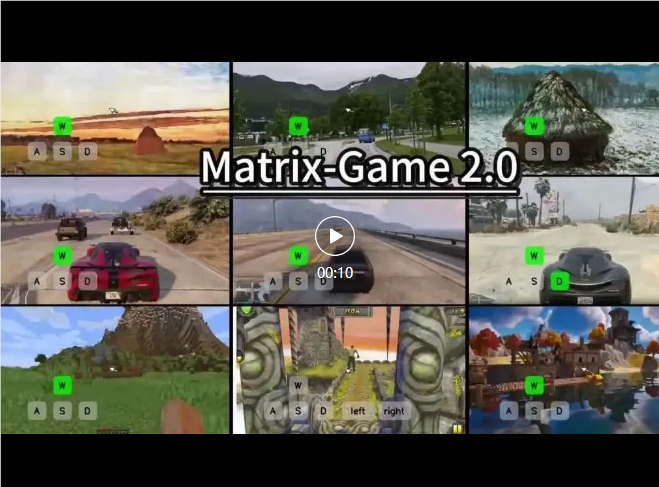
昆崙万維は、世界で初めてオープンソースの相互作用型世界モデルMatrix-Game2.0をリリースしました。リアルタイムで1分間の25fpsの高連続性動画を生成し、言語の提示なしの純粋なビジュアル駆動の相互作用をサポートしており、GTA、Minecraftなどの環境で実装されています。
【AiBaseの要点】
🚀 オープンソース初出:業界で最初の汎用シナリオリアルタイム長系列オープンソース世界モデルで、継続的な改善と全面開放を実施しています。
📹 1分間生成:25fpsの連続動画、物理法則とシーンの意味理解が大幅に向上し、ゲーム/映画/VRに直接使用可能です。
🎮 ビジュアル駆動の相互作用:言語提示を排除し、3D因果VAE+多モーダル拡散Transformerを用いて、各フレームごとにユーザーの動作に即応し、クロスドメインで多様なシナリオに適応します。
10. 昆崙万維がMatrix-3D大規模モデルをオープンソース化:1枚の画像で高品質なパノラマ動画を生成
昆崙万維はMatrix-3Dをオープンソース化しました。1枚の画像で360°の歩行可能な3Dパノラマ動画を生成し、軌跡の一貫性、幾何学的正確性を保ち、コードとデータセットを全面的に公開しています。

【AiBaseの要点】
🌐 1枚の画像で3D世界を生成:複数の視点に依存せず、単一の画像から高品質なパノラマ動画および探索可能な3Dシーンを直接生成します。
🎥 軌跡誘導の一貫性:Meshレンダリング画像で拡散モデルを駆動し、カメラの軌跡下での時空間の一貫性を保証し、偽影や遮蔽を減らします。
⚙️ 二パス再構築:スーパーサンプリング+構造最適化で丁寧に作業を行います;Transformer前馈ネットワークで高速推論を行い、品質と効率の両方を考慮します。
詳細:https://github.com/SkyworkAI/Matrix-3D