%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

【AI日報】へようこそ!ここは、あなたの人工知能の世界を探求するための毎日のガイドです。毎日、AI分野のホットなコンテンツをご紹介し、開発者に焦点を当て、技術トレンドの洞察と革新的なAI製品の応用を理解するお手伝いをします。
最新のAI製品詳細はこちら:https://top.aibase.com/
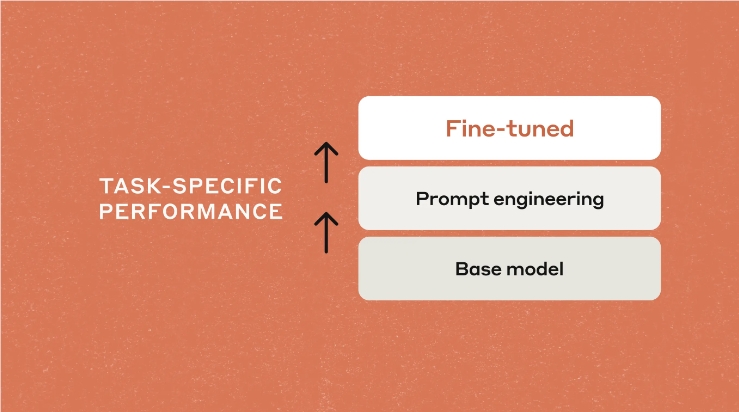
1、AnthropicがClaude 3 Haikuのファインチューニングをサポート
Anthropicは、ユーザーがAmazon Bedrockで最新のモデルClaude 3 Haikuをファインチューニングし、特定のタスクにおけるモデルの性能を向上できるようになったと発表しました。ファインチューニング機能により、ユーザーはビジネスニーズに合わせてモデルの知識と能力をカスタマイズでき、多くのメリットが得られます。
【AiBase要約:】
🛠️ ユーザーは、高品質のプロンプトと完成品を使用してファインチューニングを行い、モデルの専門性を向上させることができます。
⚡ Claude 3 Haikuは、最も高速で費用対効果の高いモデルであり、専門的なタスクに最適です。
🔒 クライアントの専有トレーニングデータはAWS環境内に保持され、安全性と低リスクが確保されます。
詳細リンク:https://aws.amazon.com/cn/bedrock/claude/
2、Heygenが口パクツールを発表 写真と音声で話したり歌ったりできる
最近、AIによる写真の「蘇生術」がネット上で話題になっています。Heygenは口パクツールを発表し、写真の人物が音声コンテンツに合わせて話したり歌ったりできるようにしました。最大20秒の音声をサポートし、唇の動きと表情が同期します。HeygenはBenchmarkのリード投資で5億ドルの資金調達を行い、勢いがあります。中国のユーザーは制限されており、一部のユーザーは失望しています。Heygenは生成AI技術を使用して動画を作成しており、すでに7400万ドルを調達しています。
【AiBase要約:】
🌟 Heygenは、写真の人物が音声コンテンツに合わせて話したり歌ったりできる口パクツールを発表しました。最大20秒の音声をサポートします。
💡 HeygenはBenchmarkのリード投資で5億ドルの資金調達を行い、勢いがあります。
🔒 中国のユーザーは制限されており、一部のユーザーは失望しています。Heygenは生成AI技術を使用して動画を作成しており、すでに7400万ドルを調達しています。
詳細リンク:https://labs.heygen.com/guest/expressive-photo-avatar
3、百度PaddleOCRがv2.8.0新バージョンを発表
PaddleOCR v2.8.0は、PaddlePaddle深層学習オープンソースフレームワーク下の文字認識開発キットとして、画期的なアップデートを発表しました。このバージョンでは、PaddleOCRアルゴリズムモデルチャレンジの優勝案を含む最先端のOCR技術が導入され、SVTRv2などのシーンテキスト認識アルゴリズムやSLANet-LCNetV2などの表認識アルゴリズムなど、OCR分野の新たな基準を確立しました。プロジェクト構造は大幅に最適化され、非コアモジュールは新しいリポジトリに移行され、プロジェクトはOCRコア技術に集中できるようになりました。新バージョンでは、過去の難問が解決され、ユーザーエクスペリエンスが向上し、安定性、互換性、パフォーマンスが強化されました。
【AiBase要約:】
🚀 PaddleOCR v2.8.0は、SVTRv2とSLANet-LCNetV2を含む最先端のOCR技術を導入し、OCR分野の新たな基準を確立しました。
🔧 プロジェクト構造が最適化され、非コアモジュールは新しいリポジトリに移行され、OCRコア技術に集中できるようになりました。
🌟 新バージョンでは過去の難問が解決され、ユーザーエクスペリエンスが向上し、安定性、互換性、パフォーマンスが強化されました。
詳細リンク:https://github.com/PaddlePaddle/PaddleOCR
4、百度、萝卜快跑の安全レベルがC919旅客機に匹敵すると発表
萝卜快跑は第6世代の無人運転車を発表し、百度Apollo ADFM大規模モデルへの接続に成功しました。安全性は人間の運転手の10倍以上に向上しています。百度は無人運転車の安全性に自信を持っており、車両と乗客にはそれぞれ500万元の保険がかけられています。運用データによると、事故発生率は人間の運転手の1/14であり、安全性の高さが際立っています。百度Apollo自動運転技術は1億キロメートル以上走行しており、重大な死傷事故は発生していません。武漢市全域、全時間帯の自動運転サービスを成功裏に実現しました。
【AiBase要約:】
🚗 無人運転車の安全性は人間の運転手の10倍以上に向上しています。
💼 車両と乗客にはそれぞれ500万元の保険がかけられています。
🛣️ 運用データによると、事故発生率は人間の運転手の1/14です。
5、智譜AIがビデオ理解モデルCogVLM2-Videoのオープンソースを発表
智譜AIが新たにオープンソース化したCogVLM2-Videoモデルは、ビデオ理解分野で顕著な進歩を遂げ、時間情報の消失問題を解決することで優れた性能を実現しました。このモデルは、ビデオ字幕生成と時間位置特定において優れた性能を発揮するだけでなく、ビデオ生成や要約などのタスクにも強力なツールを提供します。自動生成された豊富な時間位置特定データセットにより、公開されているビデオ理解ベンチマークで最新の性能を達成し、卓越した性能を示しています。

【AiBase要約:】
⏰ CogVLM2-Videoは、複数のフレームのビデオ画像とタイムスタンプをエンコーダー入力として導入することで、既存のビデオ理解モデルの時間情報消失問題における限界を解決しました。
💡 このモデルは、自動化された時間位置特定データ構築方法を利用して、時間関連のビデオQ&Aデータ3万件を生成し、トレーニングに豊富な時間位置特定データを提供します。
🚀 CogVLM2-Videoは、VideoChatGPT-BenchやZero-shot QA、MVBenchなどの定量評価指標において優れた性能を示し、複数の公開評価セットで卓越した性能を発揮しました。
詳細リンク:https://github.com/THUDM/CogVLM2
6、テンセントAIラボのプロジェクトvta-ldm:ビデオ入力から対応するオーディオを生成
テキストからビデオを生成する技術の進歩に伴い、研究者たちは、ビデオ入力と意味と時間的に整合するオーディオコンテンツを生成する方法に注目しています。テンセントAIラボはVTA-LDMモデルを発表し、暗黙的アラインメント技術により効率的なオーディオ生成ソリューションを提供し、ビデオ生成の適用範囲を拡大します。

【AiBase要約:】
🎬 研究は、ビデオ入力と意味と時間的に整合するオーディオコンテンツの生成に焦点を当てています。
🔍 ビジュアルエンコーダー、補助埋め込み、データ拡張技術の重要性について検討しました。
📈 実験結果によると、このモデルはビデオからオーディオを生成する分野で最先端のレベルに達し、関連技術の発展を促進します。
詳細リンク:https://top.aibase.com/tool/vta-ldmVTA-LDM
7、GPT-4oとSonnet-3.5が視力検査で失敗 VLMは「盲人」?
この記事は、視覚言語モデル(VLMs)の画像処理能力の限界を明らかにしています。BlindTestテストでは、それらが人間のように画像の詳細を正確に理解しているわけではないことが分かりました。この記事は、VLMsの視覚理解能力に対して慎重な姿勢を呼びかけ、AIが人間を完全に置き換えるレベルに達していないことを警告しています。
【AiBase要約:】
👓 VLMsはBlindTestテストで不十分な結果を示し、平均正確率はわずか56.20%でした。
🔍 VLMsは画像処理時に正確な空間情報が不足しており、図形の重なりや交差を判断することが困難です。
🔢 VLMsは数える際に偏りがあり、数字の5に特に精通しており、パフォーマンスは安定していません。
論文アドレス:https://arxiv.org/pdf/2407.06581
記事の詳細:https://www.chinaz.com/ainews/10186.shtml
8、商湯科技が「東風」タイ語大規模モデルを発表
商湯科技は、タイのDTGOグループとQuinnnovaと共同で、「東風」と呼ばれるタイ語大規模モデル(DTLM)を発表しました。これは、タイ語、中国語、英語の3つの言語環境で効率的に動作する世界初のAI大規模言語モデルです。このモデルは、商湯の基盤モデルと計算能力の優位性、そしてDTGOによるタイの言語文化に関する深い理解を組み合わせ、ローカライズされた生成AIエクスペリエンスを提供することを目指しています。
【AiBase要約:】
⚙️ 「東風」は、タイ語、中国語、英語の3つの言語環境で効率的に動作する世界初のAI大規模言語モデルです。
🌏 このモデルは、商湯の基盤モデルと計算能力の優位性、そしてDTGOによるタイの言語文化に関する深い理解を組み合わせ、ローカライズされた生成AIエクスペリエンスを提供することを目指しています。
💡 このモデルは、タイの個人ユーザーと企業にサービスを提供し、多言語ニーズを満たすとともに、現地の企業や政府顧客に革新的なAIソリューションを提供し、タイのAIエコシステムの発展を促進します。
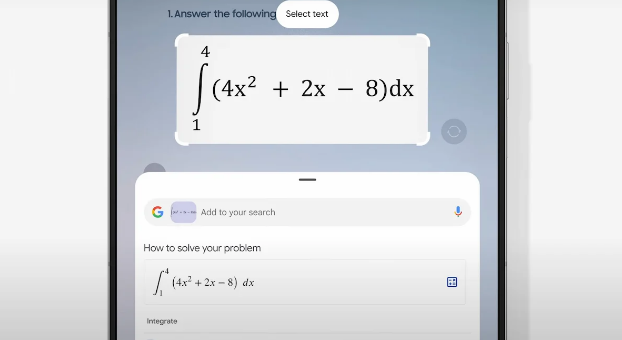
9、Samsung Galaxy AIが「数学指導」の新モードを発表 子供に解法テクニックを教える
Samsungは昨日のUnpackedイベントでGalaxy AIの大きな進歩を発表し、子供たちの宿題を支援するために設計されたAIアシスタントを発表しました。この取り組みは、Samsungの人工知能分野における野心を示しており、スマートフォン市場に新たな競争軸をもたらし、業界全体をよりスマートで教育的な方向へと推進します。
【AiBase要約:】
🚀 SamsungはGalaxy AIを発表し、最大2億台のデバイスをカバーし、野心を示しました。
🔍 宿題アシスタントはGalaxy AIの「サークル検索」機能に基づいており、子供が問題解決プロセスを完了できるように導きます。
📚 宿題アシスタントは数学の問題解決を提供し、子供の独立した思考能力を養います。
10、欧州の3つの自動車メーカーがChatGPT機能を統合 運転体験の向上を目指す
Stellantis傘下のフランスのプジョー、ドイツのオペル、英国のボクスホールは、ChatGPT人工知能技術を統合し、SoundHoundのChatAIシステムを通じて音声アシスタント機能を提供し、運転体験を向上させます。この協力は自動車技術の発展を示しており、より自然でスムーズな運転インタラクション体験をもたらします。
【AiBase要約:】
🚗 Stellantis傘下のPeugeot、Opel、VauxhallはChatGPT人工知能技術を統合し、自動車製品の機能を向上させます。
🌍 17カ国にまたがり、12言語をサポートする音声アシスタントシステムにより、より多くのドライバーに利便性を提供します。
📱 SoundHoundのChatAIにより、より自然な運転インタラクション体験がもたらされ、自動車技術の発展を促進します。
11、GoogleがGemini AIを使用してロボットをトレーニング ナビゲーションとタスク完了能力の向上を目指す
GoogleはGemini AIを使用してロボットをトレーニングし、ナビゲーションとタスク完了能力を向上させています。Gemini 1.5 Proを使用することで、ロボットは自然言語命令を実行し、ナビゲーション範囲を超えるタスクの実行を計画できます。研究によると、Geminiによりロボットはユーザーの命令を90%の成功率で実行できることが示されています。命令の処理には時間がかかりますが、これらのロボットは紛失物の発見など、さまざまなタスクを支援すると期待されています。

【AiBase要約:】
🤖 Gemini AIを使用してロボットをトレーニングし、ナビゲーションとタスク完了能力を向上させています。
🧠 Gemini 1.5 Proにより、ロボットは自然言語命令を実行できます。
🔍 研究によると、Geminiによりロボットはナビゲーション範囲を超える命令の実行を計画できることが分かりました。
12、OpenAIが初めてAGI評価基準を公開 ChatGPTはレベル1
OpenAIは、自社の大規模言語モデルの汎用人工知能(AGI)における進捗状況を追跡するために使用する内部尺度を発表し、AGI分野における野心を示しました。この取り組みは、業界にAIの発展を測定するための新たな基準を提供し、AIの安全性と倫理に関する懸念を引き起こしています。
【AiBase要約:】
🚀 OpenAIはAGI評価基準を作成し、野心を示しました。
💡 尺度は5段階に分かれており、新しいイノベーションを生み出すAIや組織全体の業務を実行するAIが含まれています。
⏳ AGIの実現時期については専門家の意見が分かれています。OpenAIはロスアラモス国立研究所と協力して、生物科学研究におけるAIの応用を探求しています。