FakeYou:克隆你的声音,生成个性化语音

站长之家
发布于AI新闻资讯 · 1 分钟阅读 · 2023年8月15号 11:03
FakeYou 是一款名为 FakeYou 的文本到语音音频剪辑工具,用户可以使用该工具生成个性化的语音内容。该工具简单易用,提供多种语音风格和场景选择,同时支持实时语音克隆和仿声模拟体验。它不仅适用于个人使用,还为内容创作者和希望为消息添加个性的人提供帮助。无论是在工作、学习还是娱乐中,FakeYou 都能满足用户的需求,让用户更好地表达自己。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

在快速发展的数字时代,虚拟角色与互动体验的融合正逐渐成为趋势。Persona Engine 应运而生,作为一款集成了 Live2D、** 大型语言模型(LLM)、 自动语音识别(ASR)、 文本转语音(TTS)** 和 ** 实时语音克隆(RVC)** 的全能工具包,为用户提供了创建生动、互动性强的数字角色的完美解决方案。这款引擎特别适合用于 VTubing、直播以及虚拟助手等应用,帮助用户在互动体验上突破传统界限。Persona Engine 使用户能够轻松实现富有表现力的实时动画,通过 Live2D 技术,虚拟角色可以以流畅的方式与观

ZyphraAI 近日发布了其最新的多语言文本到语音(TTS)模型 **Zonos-TTS**,该模型基于 **Apache2.0许可证**,完全开源且可商用。Zonos-TTS 不仅支持实时语音克隆功能,还经过20万小时的英语语音数据训练,表现出卓越的性能。Zonos-TTS 提供了两种部署方式:支持本地部署和便捷的 API 服务。对于普通用户,ZyphraAI 提供每月免费生成 **100分钟** 音频的服务;专业版用户则可以选择 **300分钟/5美元** 的套餐,超出部分按每分钟 **0.02美元** 计费。特别值得一提的是,实时语音克隆功能完全免费,且支持高音频

微信平台推出了一项新功能——“作者朗读音色”,允许公众号作者通过个性化语音为文章配音。这一功能意味着读者可以通过点击“🎧听全文”来聆听作者用自己的声音朗读的文章,增强了阅读体验的互动性和个性化。

ElevenLabs日前发布全新AI语音生成工具Voice Design,通过简单的文本描述即可创建个性化语音,开创了AI配音领域的新纪元。这款工具最大的特点是其直观的文本提示功能。用户只需描述所需声音的特征,如"温暖友好的中年女性声音,带着轻微英国口音",系统便能快速生成符合要求的语音。Voice Design支持调节多个语音参数,包括年龄、性别、口音、语调和音高等,确保生成的声音精确匹配用户需求。视频翻译:小互除了模拟真实人声,Voice Design还突破性地支持创作角色化语音。无论是精灵的空

人工智能领域的安全与伦理问题日益受到关注,Anthropic公司近期为其旗舰AI模型Claude推出了全新功能,允许其在特定场景下自主终止对话。这一功能旨在应对“持续有害或滥用性交互”,并作为Anthropic探索“模型福祉”的一部分,引发了行业内外对AI伦理的广泛讨论。Claude新功能:自主结束有害对话据Anthropic官方声明,Claude Opus4和4.1模型现已具备在“极端情况下”终止对话的能力,具体针对“持续有害或滥用性用户交互”,如涉及未成年人色情内容或大规模暴力行为的请求。 该功能于2025年8
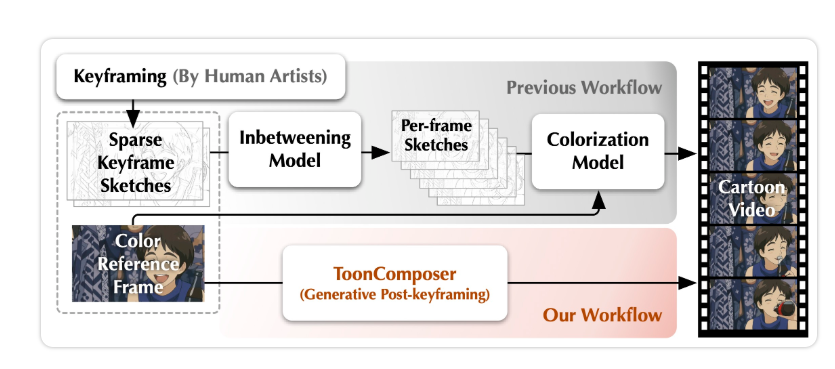
在动画制作领域,传统的动漫制作流程耗时耗力,通常需要高水平的艺术家进行关键帧绘制、补间处理和上色等多个环节。而最近,由中国香港中文大学和腾讯 PCG 的研究团队推出的 ToonComposer,将这一过程大大简化,利用生成式 AI 技术,将繁琐的手工操作转变为一个无缝的流程。 ToonComposer 的 “生成后补间” 技术,可以让用户只需提供一张草图和一帧彩色图像,便能生成完整的卡通视频,节省高达70% 的人工工作时间,让创作者可以将更多精力投入到创作本身。 在关键帧控制方面,ToonC