小紅書提出創新框架:充分利用負樣本提升大語言模型推理能力

站長之家
發布於AI新聞資訊 · 1 分鐘閱讀 · Jan 24, 2024
小紅書搜索算法團隊在AAAI2024上推出了一項旨在解決大語言模型在推理任務中黑盒屬性和龐大參數量問題的創新框架。該框架專注於利用負樣本知識來提升大語言模型的推理能力,提出了負向協助訓練(NAT)和負向校準增強(NCE)等序列化步驟,爲大語言模型應用性能提供了新思路。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

AI公司Anthropic收購Humanloop核心團隊,三位創始人及十餘名工程師加入。Humanloop專注AI提示管理、評估等服務,曾服務多家知名企業。此次收購聚焦人才引進,將強化Anthropic在企業市場的AI安全及工具開發能力。Anthropic近期還以低價向美政府提供AI服務,以應對OpenAI等競爭對手。Humanloop的評估技術契合Anthropic"安全第一"理念,雙方合作將推動負責任AI發展。

B站測試AI視頻工具"花生AI",支持文案/音頻快速生成視頻。提供兩種創作模式:智能匹配素材(3分鐘生成)和模板製作,成片質量接近UP主作品。該工具是B站AI佈局的一部分,此前已推出自研大語言模型,支持10種語言實時翻譯,準確率達90%。

根據畢馬威中國最近發佈的《首屆健康科技50》報告,中國在全球醫療大模型的發佈數量上佔據了令人矚目的70% 以上。這一數據不僅展現了中國在智能醫療領域的快速發展,也反映了大語言模型在醫療行業的廣泛應用。報告指出,目前已經發布的醫療大模型中,大語言模型的數量佔據了約65%。這類模型能夠處理和生成自然語言,對於醫療數據的分析、患者交流及科研都有着重要的支持作用。而中國的表現尤爲突出,其發佈的醫療大模型數量不僅領先於其他國家,更是在全球市場中扮演着關

近日,南京大學的周志華教授團隊發佈了一項重要研究,首次理論證明了在大語言模型中可以發現內源性獎勵模型,並有效應用強化學習(RL)來提升模型表現。當前,許多對齊方法依賴於人類反饋強化學習(RLHF),這種方法需要大量高質量的人類偏好數據來訓練獎勵模型。然而,構建這樣一個數據集不僅耗時費力,還面臨成本高昂的挑戰。因此,研究者們開始探索替代方案,其中基於 AI 反饋的強化學習(RLAIF)受到關注。這種方法利用強大的大語言模型自身生成獎勵信號,以降低對人類標
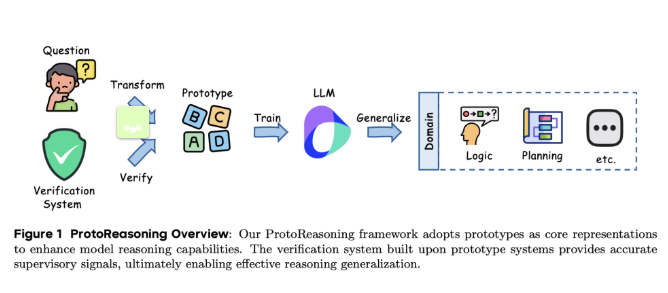
近日,字節跳動的研究與上海交通大學的團隊共同推出了名爲 ProtoReasoning 的新框架,旨在通過邏輯原型來增強大語言模型(LLMs)的推理能力。該框架利用結構化的原型表示,如 Prolog 和 PDDL,推動了跨領域推理的進展。近年來,大語言模型在跨領域推理方面取得了顯著突破,尤其是在長鏈推理技術的應用下。研究發現,這些模型在處理數學、編程等任務時,表現出了在邏輯難題和創意寫作等無關領域的優異能力。然而,這種靈活性背後的原因尚未完全明確。一種可能的解釋是,這些模型學

最近,蘋果公司發佈了一篇引發熱議的論文,指出當前的大語言模型(LLM)在推理方面存在重大缺陷。這一觀點迅速在社交媒體上引起熱議,尤其是 GitHub 的高級軟件工程師 Sean Goedecke 對此提出了強烈反對。他認爲,蘋果的結論過於片面,並不能全面反映推理模型的能力。蘋果的論文指出,在解決數學和編程等基準測試時,LLM 的表現並不可靠。蘋果研究團隊採用了漢諾塔這一經典的人工謎題,分析了推理模型在不同複雜度下的表現。研究發現,模型在面對簡單謎題時表現較好,而在複雜度