ChatGPT/GPT-4/Llama 電車難題大 PK!小模型道德感反而更高?

新智元
發布於AI新聞資訊 · 1 分鐘閱讀 · Aug 2, 2025
微軟對大語言模型的道德推理能力進行了測試,結果發現在電車問題中,尺寸較大的模型表現反而較差。然而,最強大的語言模型 GPT-4 的道德得分仍然是最高的。這一發現與研究人員最初的假設相反。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
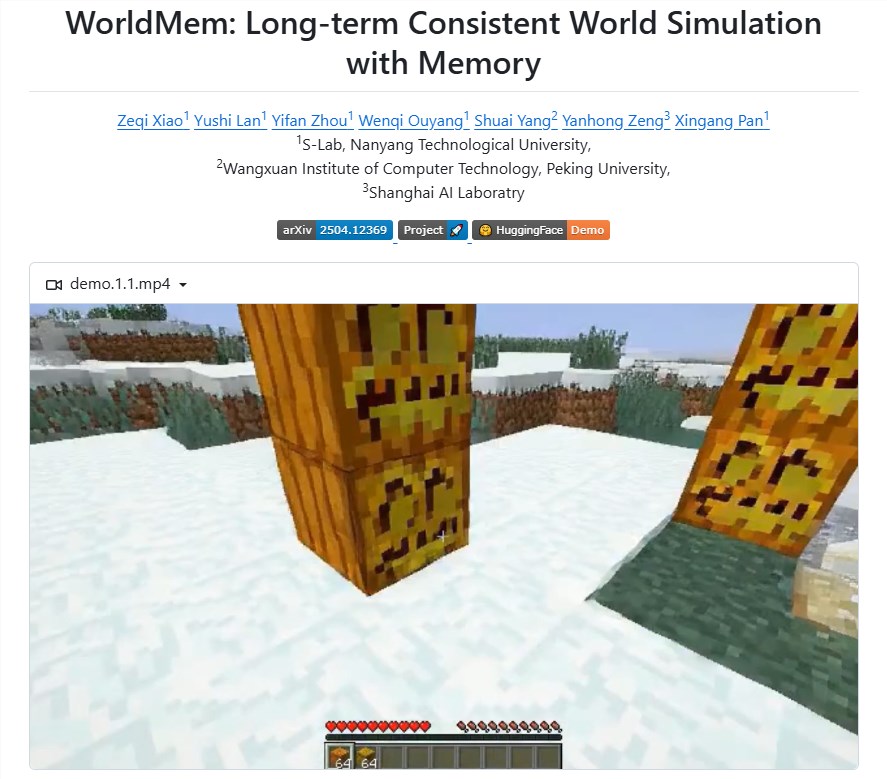
南洋理工大學等機構聯合開源"WORLDMEM"長記憶世界模型,突破傳統方法限制,通過創新記憶機制存儲場景信息,實現虛擬環境中長期一致性。模型採用條件擴散變換器架構,支持動態更新記憶庫,確保場景連貫性,並能響應動作指令。該技術顯著提升虛擬現實體驗,爲未來應用提供支持。
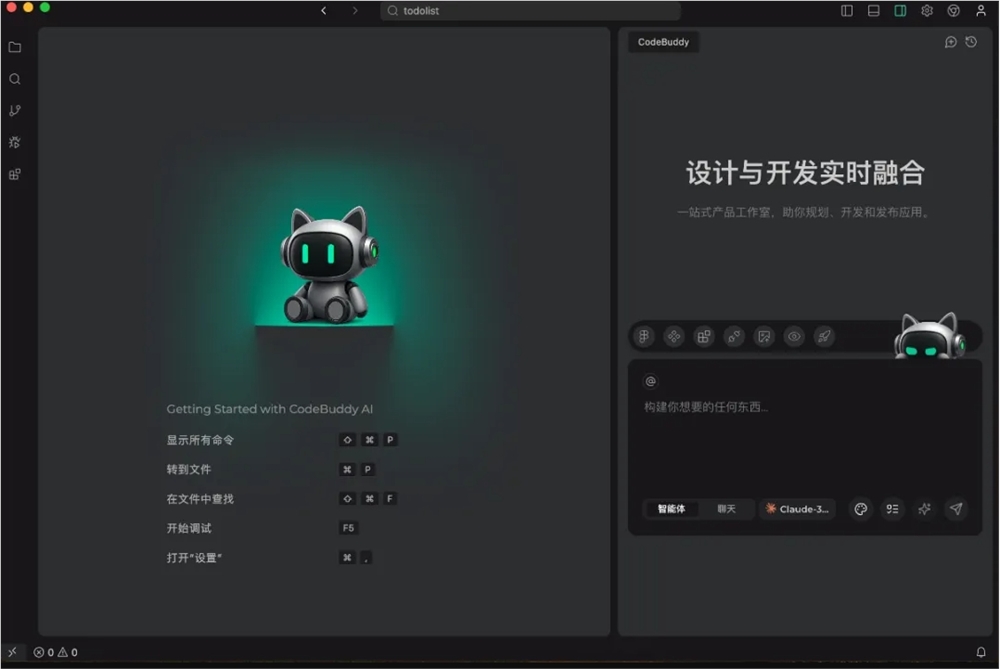
騰訊雲正式推出CodeBuddy AI IDE,這款工具被譽爲全球首位貫通產品、設計、研發的一體化AI全棧工程師,引起了業界的廣泛關注。CodeBuddy AI IDE以其獨特的工作方式,讓用戶僅通過自然語言對話提出需求,即可自動完成從產品構想到設計原型、前後端編碼直至上線部署的整個流程,真正實現了“對話即編程”的願景。 據悉,CodeBuddy AI IDE集成了國際版Claude、GPT、Gemini等主流大模型,以及國內版騰訊混元、DeepSeek等國產模型,展現了其強大的模型整合能力。用戶在使用時,只需選擇CodeBuddy的Plan模式,輸入如“幫我生成一個電商訂單管理頁”等自然語言描述,AI便能自動拆解需求,生成包括功能清單、頁面流程圖、字段建議及接口草稿在內的結構化PRD文檔,無縫銜接後續設計與開發流程。

AI代碼審查初創公司Greptile正進行3000萬美元A輪融資,估值或達1.8億美元。這家由22歲創始人Dasksh Gupta創立的公司,在完成Y Combinator孵化後已獲400萬美元種子輪融資。其核心產品是能像資深工程師一樣審查代碼的AI工具。但該領域競爭激烈,主要對手Graphite和Coderabbit分別獲得5200萬和1600萬美元融資。爲保持競爭力,Greptile團隊常工作至深夜,創始人強調"95%努力等於沒努力"。公司正通過技術優化尋求市場突破。

AMD與Tensorstack合作推出AI圖像生成軟件Amuse3.1,專爲搭載Ryzen AI XDNA2NPU的設備優化。新版本顯著提升圖像質量並降低內存佔用,24GB內存筆記本即可運行SD3.0中型模型。軟件採用無訂閱模式,支持個人用戶和小型企業免費使用。特色功能包括快速圖像迭代調整、本地離線生成,以及通過XDNA2NPU技術實現圖像分辨率翻倍提升。需配備Ryzen AI300系列或AI MAX+處理器,50TOPS算力支持。

Dia瀏覽器即將推出革命性Agent模式,引入"分身鼠標"功能實現人機並行操作。該模式通過可視化AI鼠標箭頭,讓用戶與AI可同時執行不同任務,如自動搜索、內容總結等。採用本地優先數據處理策略保障隱私安全,支持自然語言指令和個性化設置。這一創新設計重新定義了瀏覽器交互方式,將AI深度融入瀏覽體驗,顯著提升多任務處理效率,爲AI瀏覽器發展樹立新標杆。

Pika推出AI視頻特效APP,用戶上傳自拍即可一鍵生成多風格創意視頻。APP支持音頻同步表演、場景自由定製、自拍與視頻混剪等功能,還能智能生成視頻腳本。界面簡潔易用,輸出畫質高清流暢,適合短視頻平臺發佈。此次C端產品推出標誌着Pika從B端向消費級市場拓展,降低了視頻創作門檻,讓普通用戶也能體驗AI創意樂趣。該應用憑藉強大功能和易用性,有望成爲短視頻創作新寵。