「デコーダー」の研究チームは、大規模言語モデルの補助タスクにおける能力を測定するためのベンチマークであるAgentBenchを開発しました。
25種類の言語モデルをテストした結果、GPT-4が総合スコアと各分野で最高の性能を示したことが分かりました。
研究チームは、研究コミュニティが利用できるよう、ツールキット、データセット、およびベンチマーク環境も提供しています。
この研究結果は、他の商用およびオープンソースモデルの性能をさらに評価する上で非常に価値のあるものです。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

「デコーダー」の研究チームは、大規模言語モデルの補助タスクにおける能力を測定するためのベンチマークであるAgentBenchを開発しました。
25種類の言語モデルをテストした結果、GPT-4が総合スコアと各分野で最高の性能を示したことが分かりました。
研究チームは、研究コミュニティが利用できるよう、ツールキット、データセット、およびベンチマーク環境も提供しています。
この研究結果は、他の商用およびオープンソースモデルの性能をさらに評価する上で非常に価値のあるものです。

商湯科技は「日日新v6.5」やエンボディドAIプラットフォームなど新製品を発表。マルチモーダルとエージェント能力を重点展示し、AIと物理世界の融合を推進。エコパートナーとの協力契約や「算力Mall」プラットフォームも発表。....
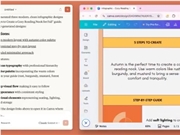
Anthropic傘下のAIサービスClaudeとデザインプラットフォームCanvaが深く協力し、テキストからビジュアルデザインへの変換機能をリリースしました。ユーザーがテキストコンテンツをアップロードすると、システムが自動的に認識し、ブランドスタイルに合ったビジュアル作品を生成し、多数のテンプレートを選べます。この機能により、デザインの门槛が大幅に低下し、個人ブローカーや企業のマーケティング担当者が迅速にプロフェッショナルなビジュアルコンテンツを作成でき、伝播効果を高めることができます。今回の協力は、AIがクリエイティブ分野で新たな突破を遂げたものであり、今後はさらなるイノベーティブなデザイン体験が期待されます。
テスラは自動運転技術の安全性向上を強調。2025年Q2レポートでは同機能使用車両の安全性が通常車の9.5倍。全車AI4ハードウェア標準装備で「事故ゼロ」を目指す。中国メディアの自動運転テスト結果への反応とみられる。....


インテルCEOが構造改革を発表、独・ポーランドのチップ工場中止、米オハイオ州工場延期、コスタリカ業務を東南アジアに統合。過剰投資を認め、15%削減・管理職50%削減で効率化。半導体競争対応のため、従業員7.5万人に削減予定。....