%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Welcome to the AIbase [AI Daily] column!
Learn about the day's major AI events in three minutes, helping you understand AI industry trends and innovative AI product applications.
Visit more AI news:https://www.aibase.com/zh
1. Tencent open-sources lightweight HuanYuan-A13B model, which can be deployed with one mid-to-low-end GPU card
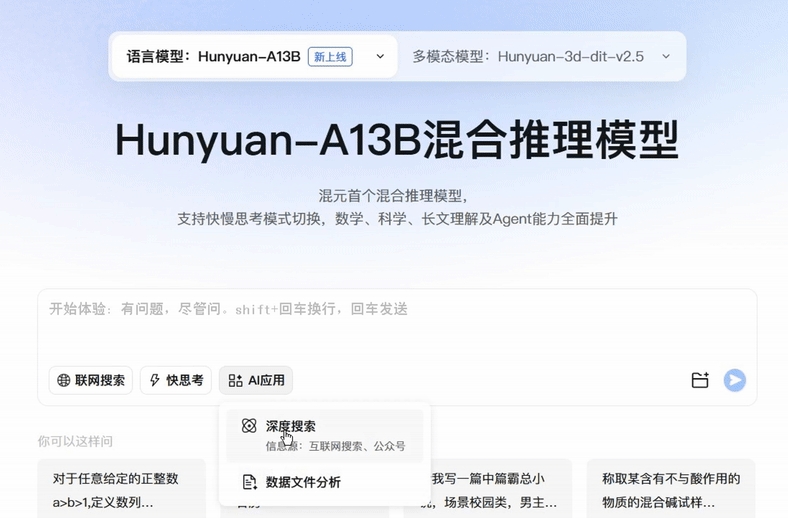
Tencent has released a new member of its HuanYuan large model family, the HuanYuan-A13B model, which uses a mixture of experts (MoE) architecture. The total parameter scale reaches 80 billion, with 13 billion activated parameters, significantly reducing inference latency and computational costs, providing a more cost-effective AI solution for individual developers and small and medium-sized enterprises. The model performs well in mathematical, scientific, and logical reasoning tasks, supporting the use of tools to generate complex instruction responses.
Experience access: https://hunyuan.tencent.com/
Open source address: https://github.com/Tencent-Hunyuan.
2. Keling AI launches the "Video Sound Effects" feature, achieving an immersive "what you see is what you hear" experience
Keling AI launched the "Video Sound Effects" feature for all its video models. Users can generate stereo sound effects while generating videos, achieving "what you see is what you hear." The upgraded "sound effect generation" function adds a "video generates sound effects" module, based on the self-developed multimodal video sound effect model Kling-Foley, achieving frame-level alignment of audio and video. This feature is now temporarily available for free to all users.
3. Black Forest震撼开源FLUX.1Kontext [dev]: Image editing comparable to GPT-4o

Black Forest Labs open-sourced the image editing model FLUX.1Kontext [dev], which is based on a 1.2 billion parameter flow matching transformer architecture and supports operation on consumer-grade hardware. Its core features are context-awareness and precise editing, allowing it to understand text and image inputs and achieve true context-based generation and editing, supporting multiple iterations of editing.
Open source address: https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev
Github: https://github.com/black-forest-labs/flux。
4. OpenAI releases new model for Deep Research API: o3/o4-mini-deep research
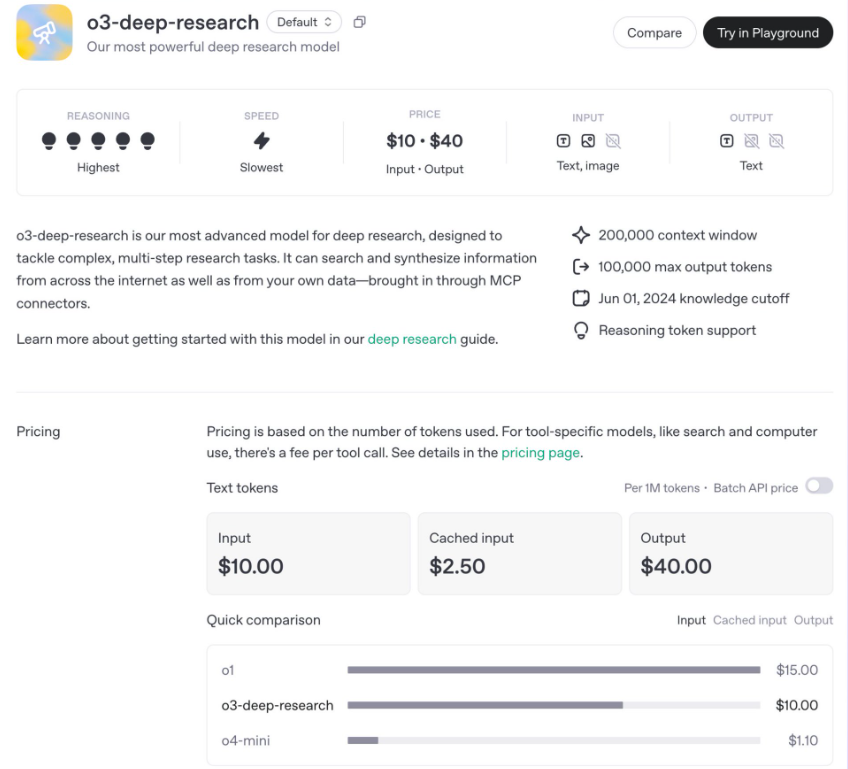
OpenAI launched two new Deep Research API models, o3-deep-research and o4-mini-deep-research, designed for advanced analysis and deep information synthesis, supporting automated web search, data analysis, code execution, and other functions. In terms of pricing, the o3 model costs between $10 and $40 per 1,000 calls, while the o4-mini is cheaper, at $2 to $8.
5. Xiaomi AI glasses start from 1999 yuan, revolutionizing smart wearables, capable of shooting, payments, and music all in one lens!

Xiaomi launched its first artificial intelligence wearable product, the Xiaomi AI Glasses, which have first-person shooting, voice assistant, and open-ear headphone functions. The glasses use electrochromic technology to provide users with a personalized experience. The design is lightweight, weighing only 40 grams, and comes with a 12-megapixel front-facing camera, supporting 2K 30 frames per second video recording and live streaming functions.
6. Thunder releases the MCP service for downloads, letting AI automatically download with just one sentence
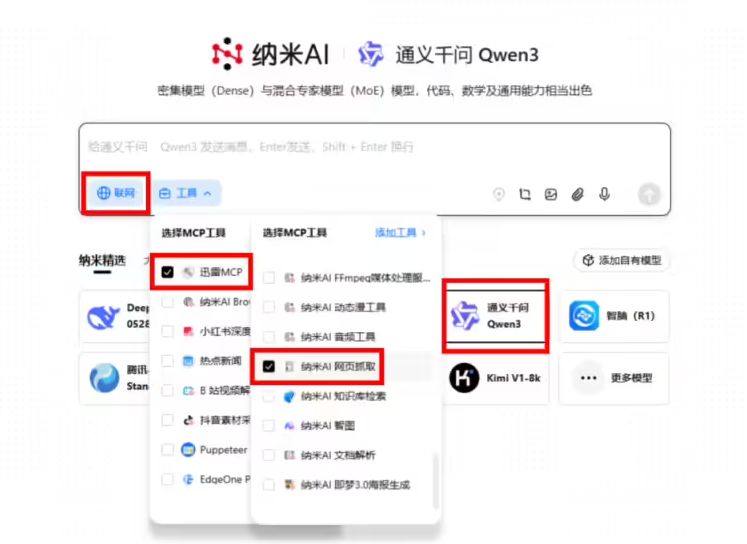
Thunder launched the MCP service for downloads, allowing users to let AI automatically complete download tasks by simply saying one sentence. This service is compatible with PC Thunder and NAS Thunder, and all users can currently use Thunder MCP for free. Thunder MCP has the ability to integrate with multiple mainstream large models, such as Nano AI, KoSpace, Cursor, and Cherry Studio.
7. One-click generation of viral videos! HeyGen AI video agent is sweeping the content creation industry!
HeyGen launched an AI video agent that automatically completes the entire video production process, from story planning, script writing, to shot selection, within minutes, delivering professional-level video content ready for direct publication. It supports various video types, simple operation processes, no need for professional video editing skills, and intelligent prompts guide users to easily upload materials and set creative needs, with the AI completing everything from scripts to final videos.
8. Major announcement! Google open-sources Gemma3n multimodal model, bringing cloud-level AI performance to mobile phones

Google has released and open-sourced the Gemma3n edge-side multimodal large model, bringing powerful multimodal capabilities to edge devices such as smartphones, tablets, and laptops. It offers two versions, E2B and E4B, with original parameter counts of 5B and 8B, respectively, but memory usage is equivalent to traditional 2B and 4B models, requiring only 2GB and 3GB of memory, respectively, to run. It natively supports processing of multimodal input, including images, audio, video, and text, and supports multilingual understanding in 140 text languages and 35 languages.
Open source address: https://huggingface.co/collections/google/gemma-3n-685065323f5984ef315c93f4




